Build an AI Lead-Generation Agent in n8n (With Real Monthly Cost)
Score, draft, and route every inbound lead automatically, for about $5 a month
AI-drafted, reviewed by Muhammad Qasim Hammad on June 14, 2026. See our AI disclosure.

Table of contents
- What is an AI lead-generation agent, and what can it actually do?
- How does the agent work inside n8n? (the nodes)
- How much does an n8n lead-gen agent cost to run?
- Which Claude model should you put in the agent?
- How do you build it in n8n, step by step?
- Step 1: Capture the lead
- Step 2: Add the AI Agent node
- Step 3: Write your system prompt
- Step 4: Add tools
- Step 5: Add the IF node for routing
- Step 6: Route alerts and connect to nurture
- What happens to a new lead? (decision map)
- Where can this go wrong?
- What should you set up this weekend?
A new lead lands in your inbox at 11pm on a Saturday, a form fill, a DM, a quick "can you help with X?" email. An n8n AI lead generation agent triages every inbound lead the moment it arrives, scoring buying intent, drafting a personalized reply, and flagging the hot ones for you, all before you wake up. The ones you reply to first are the ones you win. Manually qualifying every lead that comes in at odd hours is not a system; it is luck.
I run the same Webhook -> AI Agent pattern for email triage and WhatsApp replies. This build is the qualification front-end that feeds those flows. Here is the full spec, wired node by node, with a reproducible cost model so you know exactly what you are signing up for.
What is an AI lead-generation agent, and what can it actually do?#
An n8n AI lead generation agent is a 24/7 triage system for inbound leads: it reads each new submission, scores buying intent 1-5 against criteria you define, drafts a short personalized reply, logs it, and routes hot leads straight to you. It does not blast cold prospects. It works only on people who already raised their hand.
Three things it does that a plain Zap cannot:
- Scores contextually. The model reads the actual message, not just a field value. "We need this by Q3 and budget is approved" scores 5. "Just browsing for now" scores 1.
- Drafts, does not template. Each reply references the prospect's specific situation, not a mail-merge placeholder.
- Decides what tools to call. If the lead gives a company name, the agent may call an enrichment lookup. If the message is detailed enough, it skips it. That branching is the agent deciding, not you wiring conditional logic by hand.
 Four nodes, one afternoon, the full agent build at a glance.
Four nodes, one afternoon, the full agent build at a glance.
How does the agent work inside n8n? (the nodes)#
The agent is four connected pieces: a trigger that catches the inbound lead, an AI Agent node (with a Chat Model sub-node and tools), an IF node that routes by score, and three output branches. Every token is billed by Anthropic directly against your API key; n8n adds no markup.
Here is the wiring, top to bottom:
- Form Trigger or Webhook node catches the POST from your contact form, Typeform, or CRM. Map name, email, message, and company to named variables.
- AI Agent node, the brain. Set the Chat Model sub-node to Anthropic Claude Sonnet 4.6 (more on model choice below). Add a system prompt with your scoring rubric and reply style. Inject the lead fields as template variables.
- Tool sub-nodes inside the AI Agent:
- HTTP Request Tool, optional enrichment or web lookup for thin leads.
- Google Sheets (or any CRM node), log the lead, score, and rationale automatically.
- IF node (or Switch node), branch on score: 4-5 = hot, 2-3 = warm, 1 = cold.
- Output branches:
- Hot: Telegram or Slack node pings you immediately.
- Warm: drafted reply queued for your review (or auto-sent if you trust the rubric).
- Cold: logged to a nurture sheet or handed to your follow-up sequence.
How much does an n8n lead-gen agent cost to run?#
Qualifying and drafting personalized replies for 100 inbound leads a month costs roughly $5 in Claude API tokens on Sonnet 4.6, and $0 in n8n platform fees if you self-host under the Community edition. The table below makes the arithmetic transparent so you can reproduce it for your own lead volume.
The token assumption: the agent makes about 3 model calls per lead (score + optional tool round-trip + draft the reply), totaling roughly 9,000 input tokens (system prompt + tool schemas + the lead message + any enrichment context) and 1,500 output tokens (score rationale + drafted reply). So 1,000 leads uses approximately 9.0M input tokens and 1.5M output tokens.
Cost per 1,000 leads (as of mid-2026, June 2026, verify current prices here):
| Model | Input $/1M | Output $/1M | Cost per 1,000 leads | Best for |
|---|---|---|---|---|
| Claude Haiku 4.5 | $1.00 | $5.00 | $16.50 | High-volume, simple rubrics |
| Claude Sonnet 4.6 | $3.00 | $15.00 | $49.50 | Default: nuanced scoring + drafting |
| Claude Opus 4.8 | $5.00 | $25.00 | $82.50 | Complex reasoning edge cases |
The math for Sonnet 4.6 at 1,000 leads: (9.0 x $3.00) + (1.5 x $15.00) = $27.00 + $22.50 = $49.50. At 100 leads per month: $4.95, call it about $5.
One more factor: every lead reuses the same system prompt and tool schemas. Anthropic's prompt caching discounts repeated input at roughly 0.1x the standard rate, so your real bill is often below these table figures at any meaningful volume.
n8n Cloud Starter is €20/month if you prefer managed hosting. Self-hosted on a $5 VPS (see this setup guide) means the platform line is $0.
Enrichment is a separate cost. If you add a third-party firmographic data provider for thin leads, price it on that vendor's own page. It is not part of the $5 headline figure.
 Real costs as of mid-2026, based on Anthropic list prices.
Real costs as of mid-2026, based on Anthropic list prices.
Which Claude model should you put in the agent?#
Claude Sonnet 4.6 is the right default for lead qualification. At $3.00/$15.00 per 1M input/output tokens (as of mid-2026), it handles the nuance that scoring requires: reading between the lines of a prospect's message, personalizing a draft reply, and knowing when to call the enrichment tool versus skip it. That nuance is what separates a useful score from noise.
Use Claude Haiku 4.5 ($1.00/$5.00 per 1M tokens) if you are processing several hundred leads a month and your scoring rubric is straightforward, yes/no signal words, clear budget indicators, explicit timelines. The quality holds up for simple criteria at a fraction of the cost.
Reserve Claude Opus 4.8 ($5.00/$25.00 per 1M tokens) for edge cases where the reasoning is genuinely hard: multi-layered enterprise RFPs or highly technical qualification criteria. For most solopreneur inbound volumes, it is overkill. See the full model comparison post for a side-by-side speed and quality breakdown.
 Sonnet 4.6 is the default; Haiku suits high-volume simple rubrics.
Sonnet 4.6 is the default; Haiku suits high-volume simple rubrics.
How do you build it in n8n, step by step?#
The build takes one n8n canvas and six nodes: a Webhook trigger, the AI Agent with a Claude Chat Model, a Google Sheets log, an IF node to route by score, and a Telegram alert for hot leads. Connect them in order, test with a sample lead, then turn it on.
Step 1: Capture the lead#
Add a Form Trigger node (for a native n8n form you embed on your site) or a Webhook node if your existing contact form can POST to a URL. Under Webhook settings, set the HTTP method to POST and copy the generated URL into your form's action field. Map the incoming JSON fields to variable names: lead_name, lead_email, lead_message, lead_company.
Step 2: Add the AI Agent node#
Drop an AI Agent node onto the canvas and connect it to the trigger. Inside the node, click Add Chat Model and select Anthropic Chat Model. Choose Claude Sonnet 4.6 from the model dropdown. Paste your Anthropic API key into the credential field.
Step 3: Write your system prompt#
This is the most important step. A weak rubric produces a weak score. A concrete one produces actionable signal. Here is a copy-paste starting point:
You are a lead qualification assistant for [YOUR BUSINESS].
Score the lead's buying intent from 1 to 5 using this rubric:
5, Clear problem, explicit budget or timeline, ready to move now.
4, Specific problem, implied urgency or budget.
3, General interest, some context, no clear timeline.
2, Vague inquiry, no budget or timeline indicators.
1, Unlikely to convert (spam, wrong fit, just browsing).
Lead details:
Name: {{lead_name}}
Email: {{lead_email}}
Company: {{lead_company}}
Message: {{lead_message}}
Return a JSON object with:
- score (integer 1-5)
- rationale (one sentence)
- drafted_reply (2-3 sentence personalized reply, warm and direct, matching the score level)Adjust the rubric to your business. What makes a lead "hot" for a copywriter is different from what makes one hot for a SaaS consultant.
Step 4: Add tools#
Inside the AI Agent node, click Add Tool:
- Google Sheets tool, point it at a leads log sheet. Columns: timestamp, name, email, company, message, score, rationale, drafted reply.
- HTTP Request tool (optional), for enrichment. Point it at your preferred data provider. The agent calls this only when it decides more context would improve the score.
Step 5: Add the IF node for routing#
Connect an IF node after the AI Agent. Set three branches using the score field from the agent's JSON output:
- Hot (score >= 4): connects to your alert node.
- Warm (score 2-3): connects to the drafted-reply node.
- Cold (score = 1): connects to a nurture log or follow-up sequence.
Step 6: Route alerts and connect to nurture#
On the hot branch, add a Telegram or Slack node (see the Telegram bot guide) that sends the lead's name, score, and drafted reply as a single message. On the warm branch, queue the drafted reply for your review before it sends. Connect both to your nurture sequence once the lead is qualified.
For advanced tool/MCP wiring on the AI Agent node, see the n8n MCP agent post. To cap your token spend as the agent runs, the Claude API cost control guide covers budget guardrails.
 For inbound leads, drafted auto-replies are low-risk. Cold outreach always needs review.
For inbound leads, drafted auto-replies are low-risk. Cold outreach always needs review.
What happens to a new lead? (decision map)#
The agent scores every inbound lead, then routes it three ways: hot leads (4-5) ping you immediately, warm leads (2-3) get the drafted reply, and cold leads are logged for nurture. The diagram below maps that decision path from the moment a lead arrives to the moment it is routed.
 The agent's full decision path from new lead to routed action.
The agent's full decision path from new lead to routed action.Where can this go wrong?#
The most common failure mode is not a bug in n8n, it is a vague system prompt. If you write "score the lead 1-5 based on intent," the model will score every lead a 3. Specificity in the rubric is the entire job.
Four other things to watch:
- Hallucinated enrichment. If you give the agent an HTTP Request tool and it cannot find real public data on a company, it may fill in plausible-sounding but wrong details. Keep enrichment claims generic when the search returns nothing concrete. A confidently wrong "I see you're heading toward a Series B" kills trust fast.
- Auto-reply to inbound only. The drafted reply is safe to send (with review) to someone who messaged you. Sending it unreviewed to a purchased list is not. The compliance risk is real.
- Scoring drift. After a few weeks, sample 10 leads and check whether the scores match your judgment. If not, update the rubric. The agent is only as calibrated as the criteria you maintain.
- Speed-to-lead handoff. The agent qualifies fast, but if the hot-lead alert goes to a channel you check twice a day, you lose the speed advantage. Route hot alerts to Telegram, SMS, or Slack, whichever you actually monitor in near-real time.
After this build qualifies leads, connect the output directly to your client onboarding flow for the ones who say yes.
What should you set up this weekend?#
Start with the minimum viable version: Webhook -> AI Agent (Claude Haiku 4.5) -> Google Sheets log -> IF node -> Telegram alert. No enrichment tool, no auto-send, no cold outreach. Just scoring, logging, and a ping when something looks hot. You can add enrichment and drafted replies once the core loop works.
Once that runs cleanly on a week of real leads, upgrade to Sonnet 4.6 and add the enrichment tool for thin submissions. Then wire the warm branch to your nurture sequence so qualified leads flow automatically into follow-up.
The whole setup, excluding time spent writing a good rubric, takes an afternoon. Write one rubric version, run it on five past leads, and refine from there. That iteration is the real work.
Where to go from here: build the Webhook -> AI Agent -> IF route first, test it on your own past form submissions, then add enrichment only once scoring is stable. The model comparison post will help you decide when to move from Haiku to Sonnet. Once a lead scores hot, your follow-up sequence takes over. This agent is the front door; that one is everything after it.
Frequently asked questions
What is an AI lead generation agent?
How much does an n8n lead-gen agent cost to run?
Which Claude model is best for lead qualification?
Can the agent send cold outreach automatically?
Do I need a paid enrichment tool to build this agent?
How is this different from a lead-nurture sequence?
Does prompt caching reduce the real cost?
Sources
Primary references and vendor documentation used while drafting and reviewing this article.
Related reading

Force Structured JSON Output from AI in n8n
Your n8n AI step returns a paragraph when the next node needs clean fields. The Structured Output Parser sub-node fixes this by constraining the model to a JSON schema you define, for roughly 30 cents per 1,000 calls on Claude Haiku 4.5.

Build a Vector Store in n8n (Embeddings for RAG)
Build an n8n vector store that retrieves your own documents by meaning, not keywords. Embedding 1,000 docs costs ~1.3 cents; Supabase free-tier storage costs $0. Full node wiring and step-by-step setup inside.
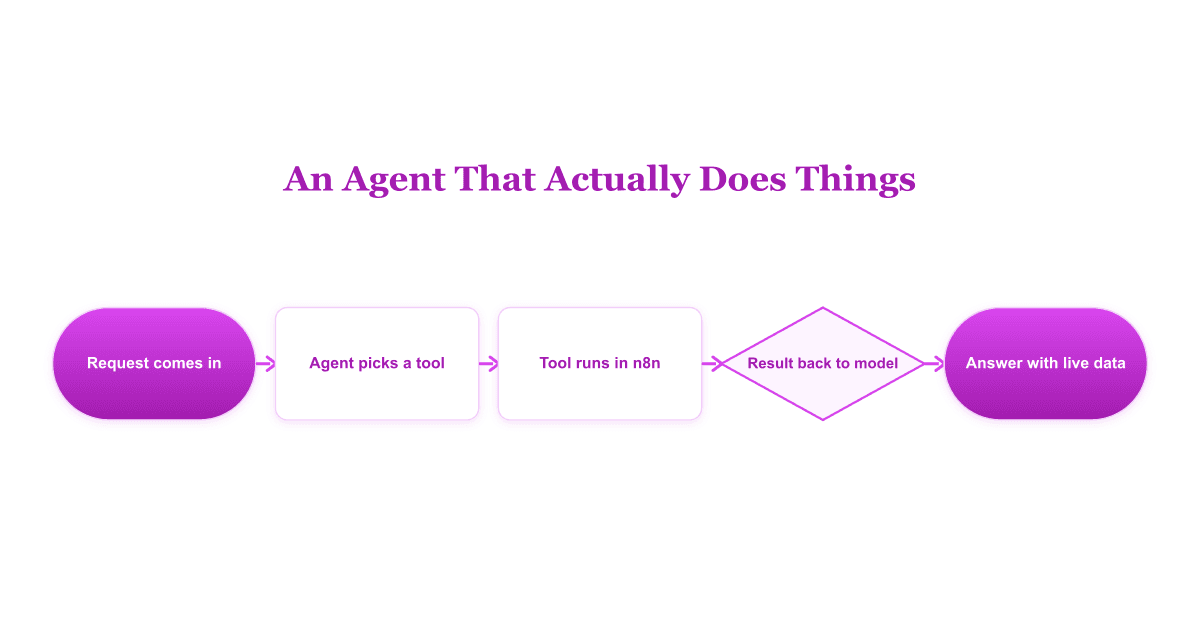
Give Your n8n AI Agent Tools (Calculator, HTTP, Workflows)
Your n8n AI Agent answers from stale training data until you attach real tools. This guide shows you exactly how to wire HTTP Request, Calculator, and Workflow tools so your agent acts on live data.